Word Cloud
Apologies for the late upload. I've had a pretty severe case of high school senioritis, and I think it might be malignant.
Back at the beginning of February, I was sitting at home bored. I had been passively kicking around an idea for a few days, and—in my catatonic stupor—I decided to test it out. My plan was to collect all of the text from each submission published to Uppagus and create a word cloud.
Long story short—a few hours later I had a janky but working Python script that scraped the site for the data I needed. After plugging the data into Mathematica—technical computing software I get through my university-to-be—and removing all the "stop" words (words like "it," "the," "at," etc.), I had three word clouds: one for poems, one for flash fiction, and one for both.
I feel I should preface them with a warning. We don't get many flash fiction submissions, at least relative to the poems. As a consequence of the low sample size, you're going to notice some bizarrely specific words in that word cloud. Also, things like capitalization and apostraphes are going to be pretty inconsistent throughout for reasons you can read about on my GitHub repository.
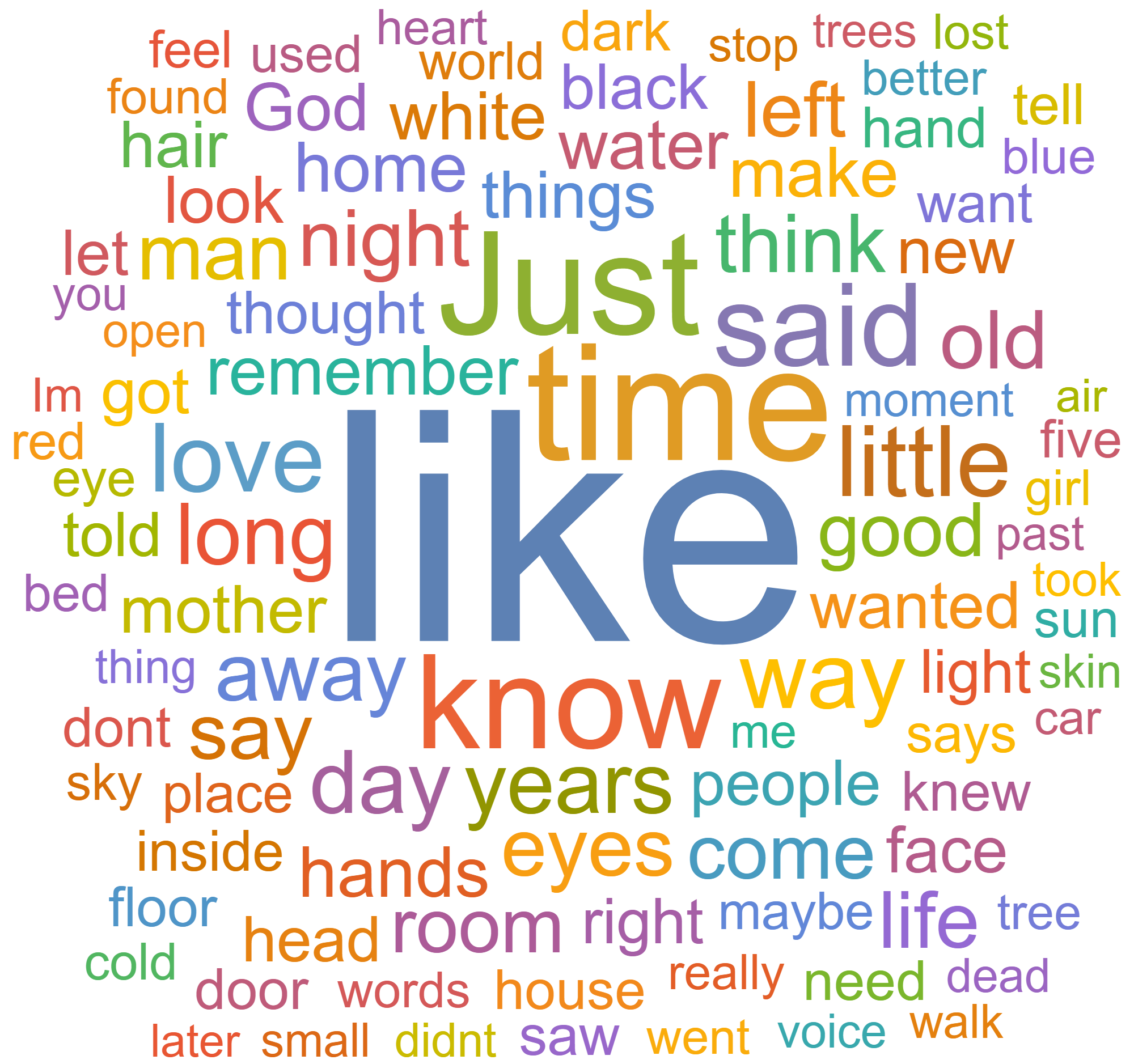
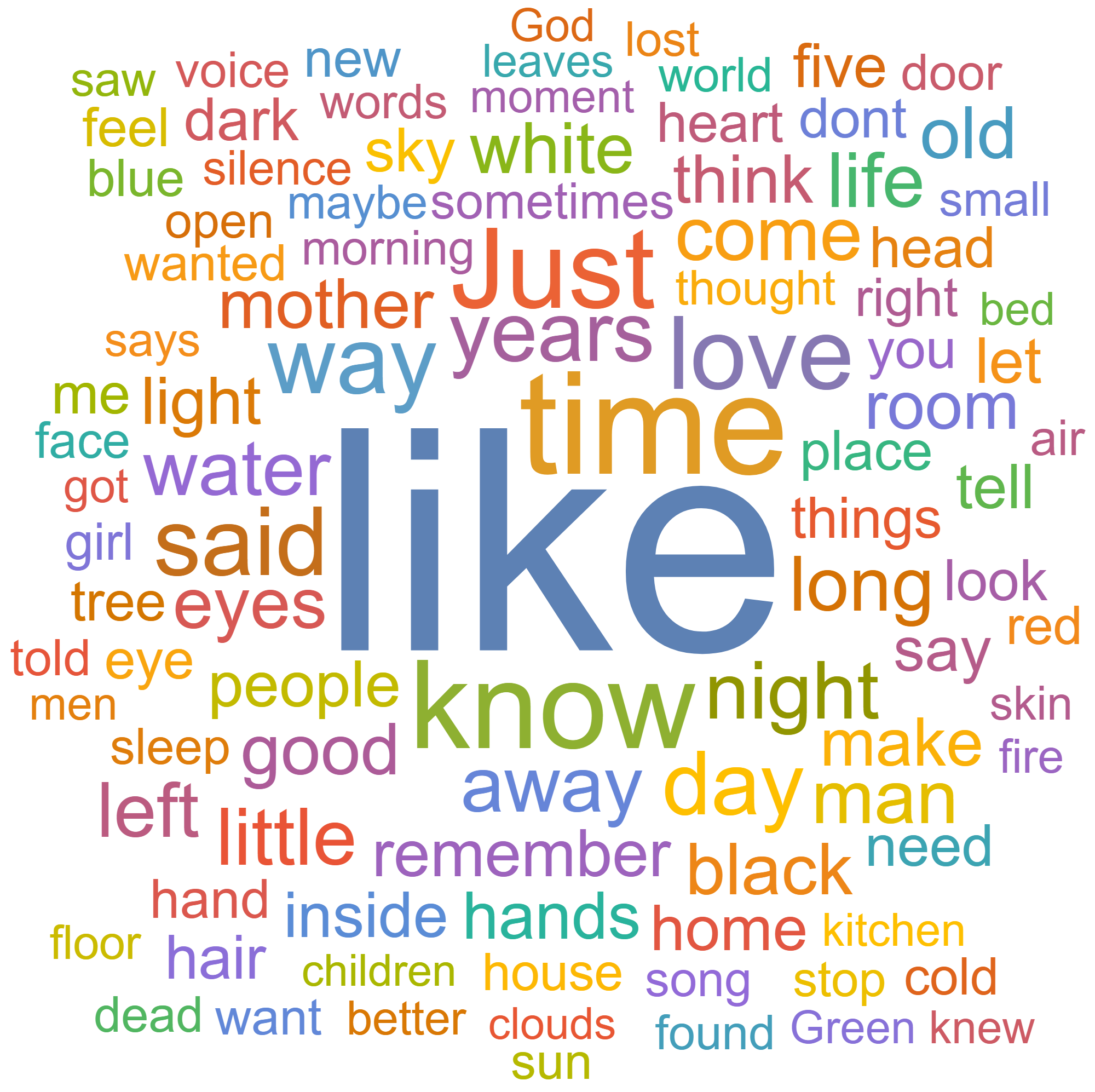
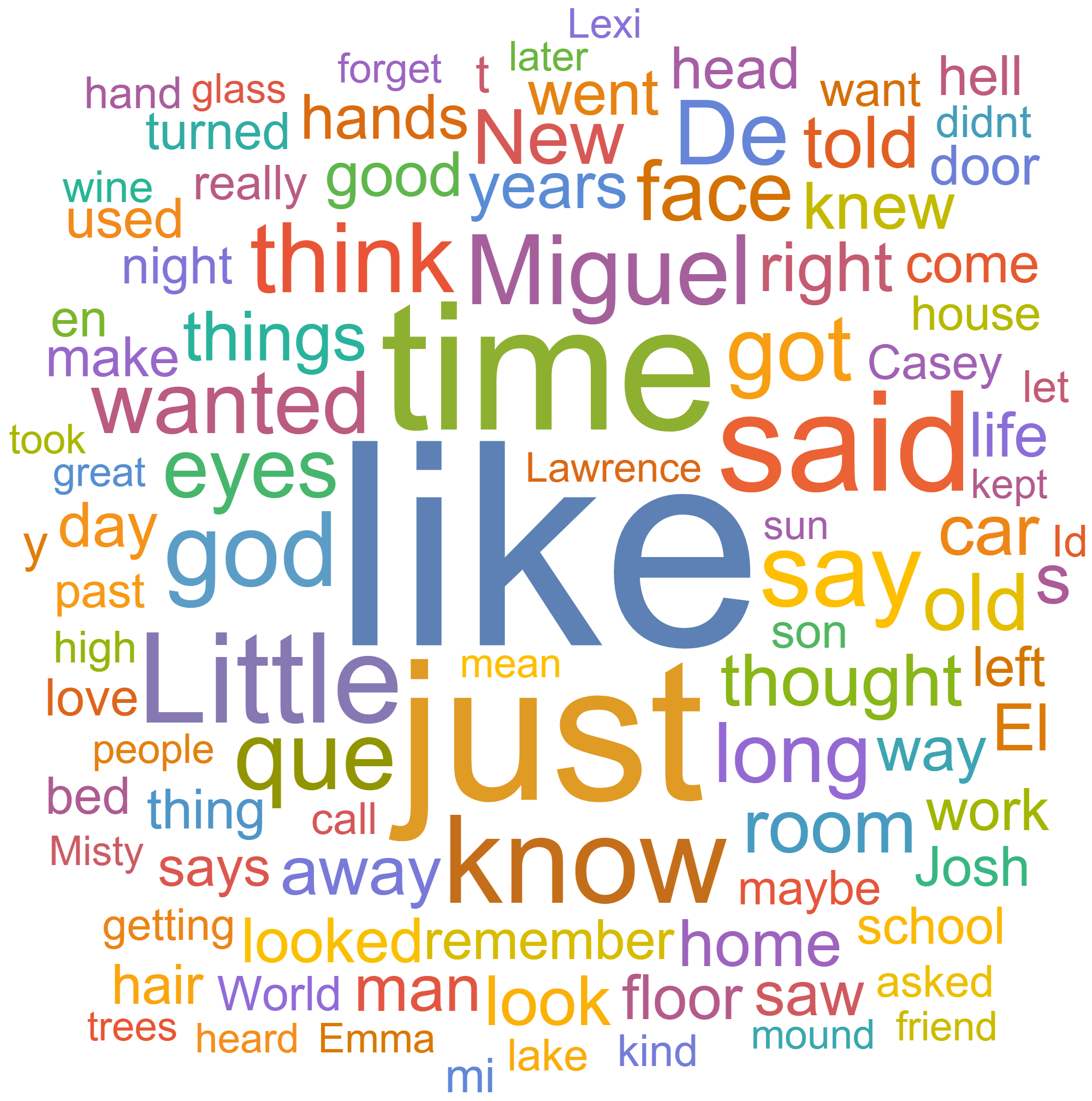
So that's that. If you want to look at the full sized images, read more about how I did it, why the results are what they are, or even improve my code (and improvement it needs—"good enough" was my mantra for this project), visit my GitHub repository.
